UPDATE SEM WHERE – Quem nunca?
 Tempo de leitura: 10 minutos
Tempo de leitura: 10 minutosOlá Pessoal,
No post de hoje vou falar sobre um assunto muito polêmico.
UPDATE SEM WHERE – Quem nunca?
Ao longo dos anos já passei por algumas situações inusitadas envolvendo esse assunto. Para ser bem sincero, eu mesmo já fiz isso em produção no começo da minha jornada profissional e a sensação não foi nada boa.
Poderia falar sobre uma série de questões envolvendo políticas de acesso do ambiente que devem ser restringidas o máximo possível para evitar que os usuários manipulem dados importantes do banco de dados e assim garantir a segurança das informações, sobre maneiras de impedir o acesso de pessoas não autorizadas na sua instância, sobre a importância dos controles de acessos, permissões, mas esse assunto vai muito além disso e muitas vezes envolve barreiras organizacionais, culturais, dentre outros aspectos que não serão abordados neste momento.
No final de tudo quando o problema é resolvido esse assunto sempre acaba virando alvo de piadas entre os colegas de trabalho.

Ainda bem que em alguns casos é possível reverter, não é mesmo?
Faz parte do show. Poderia marcar alguns amigos que já vivenciaram situações semelhantes ou até mesmo que já fizeram isso em ambientes de produção, mas a intenção aqui não é expor ninguém, quem nunca errou que atire a primeira pedra.
Vamos lá, o objetivo desse post é trazer algumas maneiras de recuperar os seus dados mediante a esse cenário inusitado.
O maior conselho que dou para esses casos é mantenha a calma OK. Entrar em desespero não vai ajudar em nada.
Vamos simular esse cenário em laboratório e explorar algumas possibilidades de como recuperar os seus dados quando esse tipo de situação acontecer.
Primeiramente, é importante dizer que você precisa manter uma política de Backup do seu ambiente, sem os dados íntegros em algum lugar antes da tragédia as alternativas para recuperar os dados vão ficando cada vez mais restritas.
Para começar, realizei a criação de uma base chamada “teste” no meu ambiente, coloquei ela em Recovery FULL, criei uma tabela qualquer chamada “USUARIO” e na sequência inseri alguns registros fictícios.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
CREATE DATABASE teste; GO ALTER DATABASE teste SET RECOVERY FULL; go USE teste; GO CREATE TABLE USUARIO ( ID INT, NOME VARCHAR(200), DT_NASC DATE, SEXO CHAR(1) ); INSERT INTO USUARIO ( ID, NOME, DT_NASC, SEXO ) VALUES (1,'GUSTAVO LAROCCA', '21/06/1991', 'M'), (2,'LUIZ LIMA', '01/05/1990', 'F'), (3,'FELIPE PORTELLA', '04/03/1980', 'F'), (4,'ANDERSON AROUCHA', '01/10/1988', 'F'); |
Gustavo, Recovery FULL? O que é isso?
É uma propriedade do banco de dados (SQL Server) que determina como as transações serão registradas.
Existem 03 tipos: SIMPLE, FULL e BULK_LOGGED.
O modelo FULL é o que vejo sendo mais utilizado e vamos focar nele nesse artigo OK.
Em resumo, todas as operações que são realizadas no seu banco de dados serão armazenadas no log de transações, ele registra tudo o que acontece por debaixo dos panos, com esta propriedade habilitada como “FULL” é permitido que você faça o Backup desse LOG em pequenos pedaços, assim é possível recuperar os dados em um ponto específico no tempo e ir armazenando uma parcela dos seus dados de maneira incremental à medida que as transações vão acontecendo e os backups de log vão sendo feitos.
Tem um post muito bem explicado do Vinicius Fonseca que ele ilustra as características de cada modelo de recuperação e esclarece dúvidas muito comuns.
Segue o link do artigo:
Também não poderia deixar de citar um post do meu amigo e companheiro de trabalho Luiz Lima sobre um script muito útil que ele desenvolveu para fazer a recuperação point-in-time de vários arquivos de LOG (que resolve a dor de muita gente) e demonstra também maneiras de como solucionar esse tipo de problema.
Link da postagem:
Voltando ao nosso contexto criado apenas para servir de ilustração. Agora vamos começar a nossa brincadeira.
Partindo do pressuposto que você tenha ao menos um Backup FULL do seu banco de dados, vou realizar um Backup aqui do meu banco antes de iniciarmos a nossa demonstração.
|
1 2 |
BACKUP DATABASE teste TO DISK = 'D:\BACKUP_TESTE_BLOG\teste_blog.bak' WITH COMPRESSION,STATS =5 |

Nossa tabela está por enquanto com os seguintes registros:
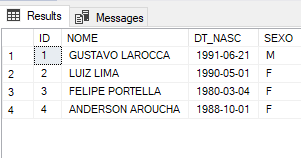
Vamos cadastrar mais um usuário.
|
1 2 3 4 5 6 7 |
INSERT INTO USUARIO ( NOME, DT_NASC, SEXO ) VALUES('GABY SARAIVA','25/08/1989','F') |
Imagine que você em determinado momento do dia identificou uma inconsistência no cadastro do usuário “Felipe Portella”, esse nome foi registrado incorretamente e deveria ter apenas uma letra “L” no sobrenome, ficando “Felipe Portela”.
Você decide então corrigir pelo banco. Porém, no calor do momento acabou esquecendo do WHERE no seu UPDATE.
|
1 |
UPDATE usuario SET nome = 'FELIPE PORTELA' |

Viva a REDGATE, no meu ambiente tenho o SQL Prompt, olha só o que essa ferramenta maravilhosa me alertou quando tentei executar o UPDATE SEM WHERE.
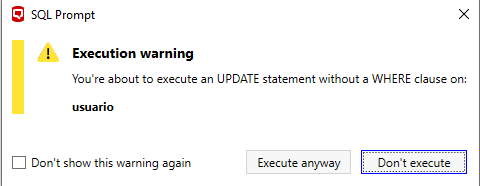
Já pensou se algo semelhante viesse embarcado no nosso querido Management Studio por padrão? Poderia ter evitado tantos problemas e salvado tantos empregos por aí, não é mesmo?
Alô Microsoft, fica a dica. ?
Mas infelizmente você não teve a mesma sorte que eu de ser avisado por uma ferramenta e acabou executando o UPDATE acidental.
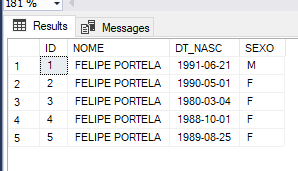
Eita, aí lascou, agora todos os usuários se chamam “Felipe Portela”.
– Ahh mas nesse caso, está fácil Gustavo, eu posso ir fazendo o UPDATE em cada registro e ir corrigindo um por um.
Sim, é uma alternativa, mas imagine que você tenha feito isso em uma tabela do banco de produção com milhões de registros, quanto tempo você iria levar para corrigir um por um?
Imagine se essa tabela fosse algo crítico do sistema, como um histórico de contas a receber?
– Bom, mas nem tudo está perdido né? foi feito um Backup FULL do banco antes de começar os procedimentos não foi?
Opa, bem observado, foi feito um Backup FULL sim, mas lembre-se que mais um usuário foi registrado na tabela “USUARIO” depois do BACKUP FULL.
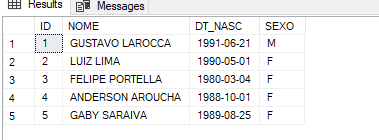
– Nossa, é verdade e agora?
Este cenário, é o que mais vejo por aí… os sistemas não vão parar de registrar dados depois que você cometeu um acidente, os registros continuarão a serem alimentados no banco.
– Tá bom Gustavo, mas e aí? o que eu faço? Se eu voltar o Backup FULL vou ter apenas os 04 últimos registros, e o meu novo registro que foi cadastrado depois, vou perder?
Vou apresentar algumas maneiras de como você pode sair desse tipo de situação.
Lembra do Recovery FULL? Então, agora vamos ver como ele pode nos ajudar na prática.
Bom, primeiramente vamos fazer um Backup de LOG do nosso banco (Já começa por ai, no Recovery SIMPLE isso não é possível).
|
1 2 |
BACKUP LOG teste TO DISK = 'D:\BACKUP_TESTE_BLOG\teste_log_1.trn' WITH COMPRESSION, STATS = 5 |
Ah Gustavo, mas do que vai adiantar fazer um BACKUP de LOG agora se o problema já aconteceu?
Veja só. Lembra que eu comentei que o log de transações registra tudo o que acontece por debaixo dos panos envolvendo as transações do banco de dados?
Pois é, existe uma função (não documentada) chamada FN_DBLOG que poderá te ajudar bastante.
Com ela é possível você visualizar o histórico das últimas transações que aconteceram no SQL Server da sua base de dados.
– Nossa Gustavo, está começando a ficar interessante, conta mais.
|
1 2 3 4 5 6 7 8 9 10 11 |
-- INFORMAÇÕES BASICAS DA FN_DBLOG SELECT [CURRENT LSN], [OPERATION], [CONTEXT], [Begin Time], [End Time], [SPID], [Transaction ID], [AllocUnitName] FROM FN_DBLOG(NULL, NULL); |
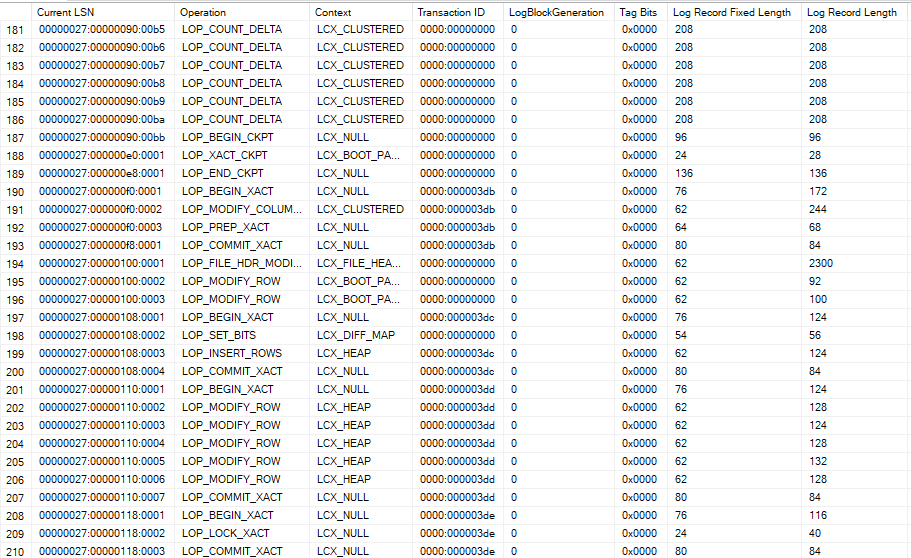
Por meio desse SELECT nessa função interna, conseguimos visualizar o log de transações vigente das nossas transações.
A tabela abaixo, me ajudou um pouco a entender o que representa algumas colunas dessa função.
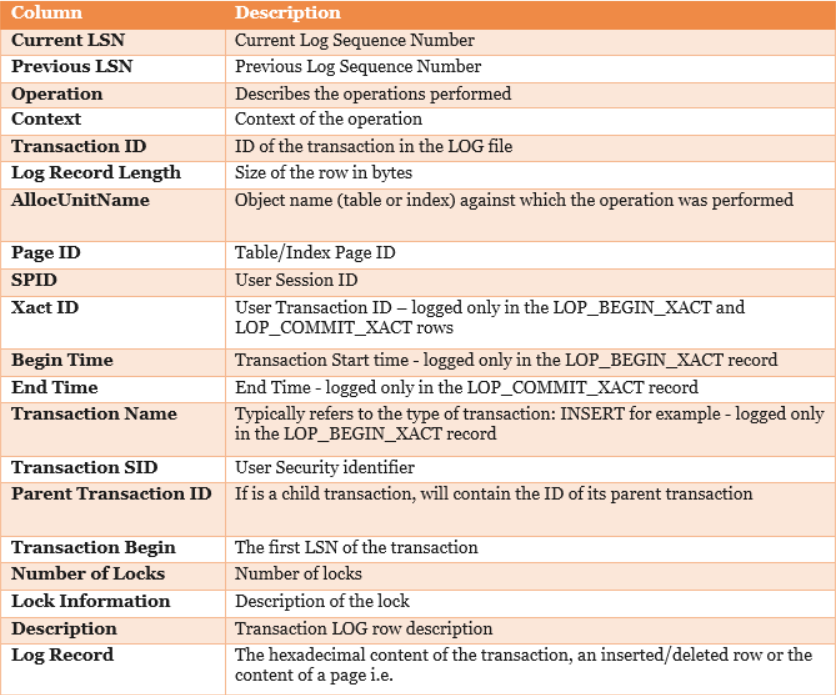
Link do artigo dessa imagem (que por sinal é muito bom) :
https://blog.coeo.com/inside-the-transaction-log-file
– Tá Gustavo, mas isso ainda está muito confuso, o que você vai fazer com esse monte de informações?
Bom, vamos lá. Partindo do pressuposto que nesses logs nós temos as últimas transações que aconteceram antes do checkpoint do log de transações, nós precisamos tentar identificar qual foi o momento em que o nosso UPDATE SEM WHERE ocorreu para corrigir, correto?
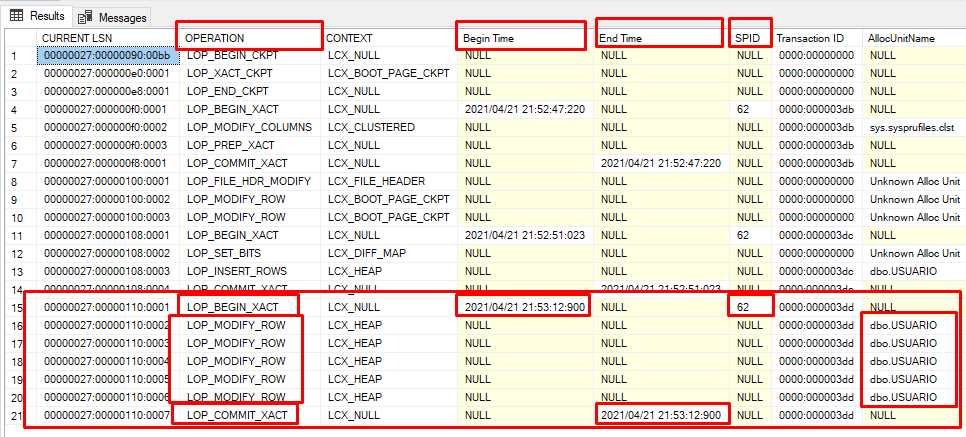
Observando com mais cuidado, podemos inferir algumas coisas.
Por exemplo, se observarmos nossas últimas transações na coluna OPERATION, estão com o valor LOP_MODIFY_ROW (Modificação de linhas). Repare que temos 05 registros em sequência o que provavelmente indica que o nosso UPDATE SEM WHERE aconteceu nesse bloco de registros, veja também que toda transação começa com o LOP_BEGIN_XACT e termina com o LOP_COMMIT_XACT. (Isso nos leva a crer que por debaixo dos panos o SQL Server trabalha com transações explicitas).
Outros fatos curiosos são as colunas BEGIN TIME e END TIME, que mostram o horário que começou e que terminou a nossa transação e a coluna AllocUnitNAme mostra o objeto do nosso banco de dados que sofreu as modificações.
– Beleza Gustavo, está ficando interessante, conte-me mais.
Já sabemos o exato momento que o nosso UPDATE SEM WHERE aconteceu, o que podemos fazer agora?
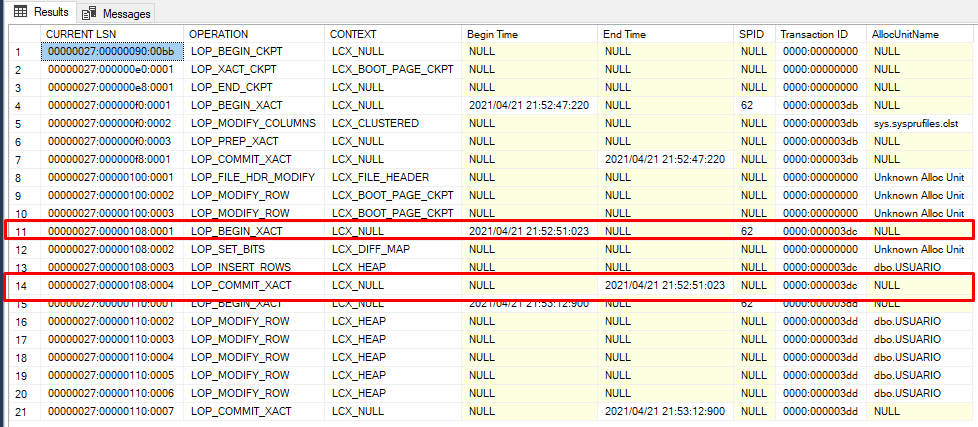
Se analisarmos um pouco mais para trás na imagem, nós temos na coluna OPERATION outra operação que começa na linha 11 e termina na linha 14. Veja que entre o meio das transações temos o valor LOP_INSERT_ROWS que provavelmente é o ponto onde havíamos inserido o nosso último registro.
Na primeira coluna, nós temos o CURRENT_LSN (que é um ponteiro do nosso log de transações).
LSN significa “Log Sequence Number”.
Vamos anotar o nosso CURRENT_LSN da linha que identificamos o COMMIT do nosso último registro válido, nesse caso a linha 14.
– Registro anotado Gustavo: 00000027:00000108:0004
Show, agora vamos fazer o seguinte. Iremos restaurar o nosso Backup FULL com outro nome e como NORECOVERY para na sequência restaurar o nosso Backup de LOG.
|
1 2 3 4 5 6 7 8 |
RESTORE DATABASE [teste_blog] FROM DISK = N'D:\BACKUP_TESTE_BLOG\teste_blog.bak' WITH FILE = 1, MOVE N'teste' TO N'C:\Program Files\Microsoft SQL Server\MSSQL14.MSSQLSERVER\MSSQL\DATA\teste_blog.mdf', MOVE N'teste_log' TO N'C:\Program Files\Microsoft SQL Server\MSSQL14.MSSQLSERVER\MSSQL\DATA\teste_blog_log.ldf', NORECOVERY,NOUNLOAD,REPLACE,STATS = 5; |
Maravilha, é agora que vem a salvação, vamos restaurar o nosso Backup de LOG, no entanto, lembra que executamos ele depois que o nosso UPDATE SEM WHERE aconteceu? Pois é, mas aí é que está a mágica, existem parâmetros que podemos executar para “pausar” a nossa restauração de log em um momento específico. Vou demostrar algumas formas de como podemos recuperar o nosso banco no momento exato antes do incidente.
Lembra do LSN que você anotou? Vamos usar ele nesse exato momento.
|
1 2 3 4 5 |
RESTORE DATABASE [teste_blog] FROM DISK = N'D:\BACKUP_TESTE_BLOG\teste_log_1.trn' WITH RECOVERY, STOPATMARK = 'lsn:0x00000027:00000108:0004', STATS = 5; |
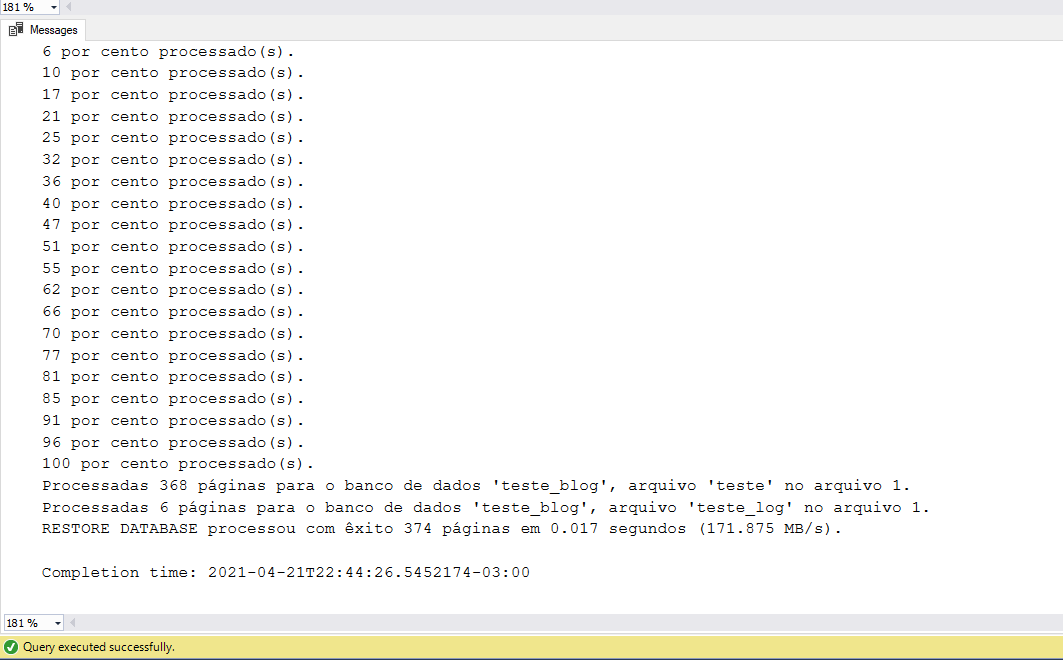
O parâmetro STOPATMARK combinado com a instrução LSN irá parar o restore exatamente na marca que solicitamos.
Dica: Coloque sempre os registros dessa forma lsn:0x quando for restaurar os dados a partir de uma posição LSN.
Agora vamos conferir o nosso banco restaurado para validar se deu tudo certo com a nossa recuperação de dados.
|
1 2 3 |
USE teste_Blog GO SELECT * FROM USUARIO; |
Eita!! Que beleza, meus dados estão aí de volta, intactos.
Existe uma outra função, também não documentada chamada FN_DUMP_DBLOG que te permite fazer basicamente a mesma coisa que vimos na FN_DBLOG, porém, nela você lê essas mesmas informações diretamente do seu Backup de LOG, legal né?
Segue um exemplo de leitura do meu arquivo gerado.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT * FROM fn_dump_dblog ( DEFAULT, DEFAULT, DEFAULT, DEFAULT, 'D:\BACKUP_TESTE_BLOG\teste_log_1.trn', DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT ); |
– Gustavo, então você está me dizendo que se for feito checkpoint do meu log de transações atual é possível ler também essas mesmas informações diretamente do meu arquivo de BACKUP de LOG, localizar em qual posição estavam os meus registros e dizer em qual o ponto exato eu quero que o meu restore pare?
Sim, exatamente!
Existe uma série fantástica no blog do Rodrigo Ribeiro dividida em 6 partes -“Recuperando dados deletados do SQL Server sem Backup Full”, na qual se encaixa perfeitamente nesse contexto que estamos vendo agora e ele aborda em detalhes alguns conceitos que vimos até o momento e muito mais.
https://thesqltimes.com/blog/series/recuperando-dados-deletados-sem-backup-full/
Não deixem de conferir!!
Uma outra maneira bem legal de utilizar o parâmetro STOPATMARK é criando uma marcação dentro de uma transação explicita.
Vamos lá, primeiro eu abro uma transação explicita, informando a minha marcação
|
1 2 3 4 5 6 |
BEGIN TRANSACTION TESTE_MARCACAO WITH MARK 'TESTE_MARCACAO' INSERT INTO USUARIO (ID,NOME,DT_NASC,SEXO) VALUES (06,'TESTE','01/01/2000','M'); COMMIT TRANSACTION TESTE_MARCACAO |
Você pode consultar as marcações no banco msdb na tabela “logmarkhistory”
|
1 2 3 4 5 6 7 8 |
-- CONSULTA AS MARCAÇÕES CRIADAS NO CATÁLOGO DA MSDB SELECT DATABASE_NAME, MARK_NAME, DESCRIPTION, USER_NAME, LSN, MARK_NAME FROM msdb..LOGMARKHISTORY; |

Agora vamos DELETAR toda a nossa tabela “USUARIO”.
|
1 |
DELETE FROM USUARIO |
Feito isso, vamos fazer um novo backup de LOG para simular a recuperação.
|
1 2 3 4 |
BACKUP LOG teste TO DISK = 'D:\BACKUP_TESTE_BLOG\teste_log_2.trn' WITH COMPRESSION, STATS = 5; |
Agora vamos repetir o processo de restauração já demonstrado anteriormente. Restauramos o BACKUP FULL e na sequência vamos partir para o LOG (desta vez utilizando a nossa marcação como ponto de parada).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
--RESTORE DO BACKUP FULL RESTORE DATABASE [teste_blog] FROM DISK = N'D:\BACKUP_TESTE_BLOG\teste_blog.bak' WITH FILE = 1, MOVE N'teste' TO N'C:\Program Files\Microsoft SQL Server\MSSQL14.MSSQLSERVER\MSSQL\DATA\teste_blog.mdf', MOVE N'teste_log' TO N'C:\Program Files\Microsoft SQL Server\MSSQL14.MSSQLSERVER\MSSQL\DATA\teste_blog_log.ldf', NORECOVERY,NOUNLOAD,REPLACE,STATS = 5; --RESTORE DO LOG COM A MARCAÇÃO CRIADA RESTORE LOG [teste_blog] FROM DISK = N'D:\BACKUP_TESTE_BLOG\teste_log_2.trn' WITH STOPATMARK = 'TESTE_MARCACAO', STATS = 5; |
Vamos consultar os nossos dados agora.
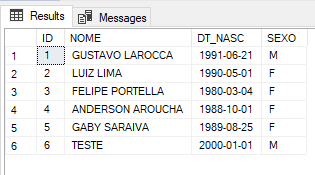
Opa, ai sim ein!! ?
Agora é só levar os dados do seu backup recuperado para o seu banco de produção.
E no final de tudo isso é sacanagem deixar o nome do meu amigo Felipe Portela errado né, ele iria me matar quando visse.
|
1 2 3 |
UPDATE USUARIO SET NOME = 'FELIPE PORTELA' WHERE ID = 3; |
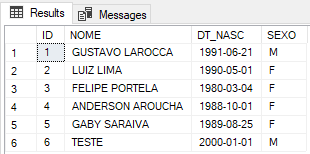
Pronto, corrigido!
Show, mas é como eu disse no início do post, no mundo real o banco de dados não vai parar para você utilizar essas opções, talvez localizar essas informações em um ambiente cheio de transações pode ser um trabalho bem árduo e demorado. No caso das transações com marcações é uma boa pedida, porém, nunca vi ninguém usando isso até hoje.
O jeito mais simples de parar o seu Backup de LOG no tempo no meu ponto de vista é através do parâmetro STOPAT, na qual você define a data e o horário que deseja que o seu LOG pare de restaurar.
Essa outra forma mencionada com o parâmetro STOPAT podemos ver no blog do Luiz Lima no post dele que comentei no início do texto.
Bom, é isso espero que tenham gostado!
Qualquer dúvida deixe os comentários.
Gustavo Larocca
Consultor SQL Server






6 comentários
Boa!!! Esse é o tipo de post que salva empregos. Hahaha
Muito obrigado Anderson!! Tmj!
Abraço
Muito legal seu artigo.
Muito obrigado Uakiti!
Muito bom Post meu amigo, sucesso.. você vai longe!
Obrigado meu irmão!! que bom que gostou, vamos juntos!
Abraço