Índice Columnstore – Herói ou Vilão?
 Tempo de leitura: 13 minutos
Tempo de leitura: 13 minutosOlá Pessoal,
Espero que estejam todos bem! 😀
No post de hoje vou falar sobre um assunto que sempre gera discussão entre DBAs e desenvolvedores de BI.
Ah, os Columnstore Indexes… Essa funcionalidade que chegou no SQL Server 2012 e desde então vem dividindo opiniões. Uns chamam de revolução, outros de dor de cabeça. Mas afinal, eles são heróis ou vilões na nossa batalha diária para obter mais performance?
Bom, como sempre digo, depende. E hoje vou te explicar quando eles podem salvar o seu dia e quando podem te dar uma bela dor de cabeça.
Ao longo dos anos já vi muita gente implementando Columnstore em lugares que não deveriam, e também vi gente perdendo oportunidades incríveis de melhorar performance por não conhecer essa tecnologia. Para ser bem sincero, eu mesmo já passei por situações onde achei que seria a solução de todos os problemas e acabei me frustrando.
O maior conselho que dou é: teste sempre em laboratório primeiro. Não saia implementando em produção sem entender o comportamento no seu cenário específico.
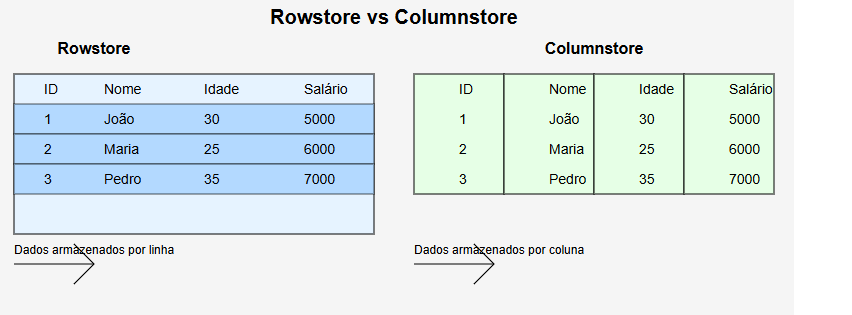
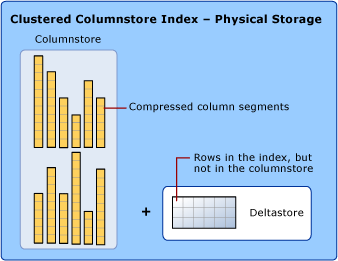
O que são esses tais Columnstore Indexes?
Já os Columnstore Indexes fazem o contrário: eles armazenam os dados por coluna. É como se você pegasse aquele Excel e, ao invés de ler linha por linha, você lesse coluna por coluna.
Vou dar um exemplo prático para ficar mais claro:
Os Columnstore Indexes não são apenas uma forma diferente de armazenar dados. Eles trazem uma arquitetura completamente nova que você precisa entender:
Rowgroups e Segments
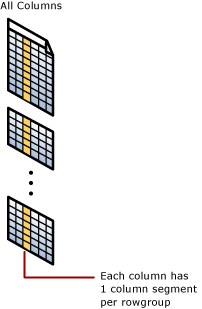
Existe também o Deltastore, que armazena dados temporários em formato rowstore até ter registros suficientes para formar um rowgroup completo. É como se fosse uma “sala de espera” para os dados.
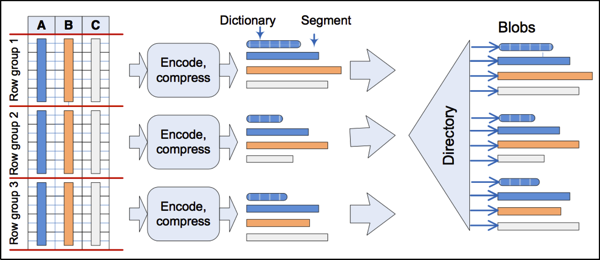
O processo de compressão
Ele usa algoritmos específicos como Dictionary encoding e run-length encoding, valores repetidos são armazenados uma única vez.
Vamos entender um pouco mais a fundo como funcionam os algoritmos de Dictionary encoding e Run-Length Encoding (RLE).
O Dictionary encoding é um algoritmo de compressão que funciona criando um dicionário de valores únicos em uma coluna. Cada valor único é atribuído a um identificador numérico, e em vez de armazenar o valor real, o SQL Server armazena o identificador numérico. Isso é especialmente útil em colunas com muitos valores repetidos, como no exemplo da coluna de estado civil que mencionei anteriormente. Com o Dictionary encoding, o SQL Server pode armazenar apenas uma vez cada valor único e referenciá-lo várias vezes, reduzindo significativamente o espaço de armazenamento necessário.
Já o Run-Length Encoding (RLE) é um algoritmo de compressão que funciona identificando sequências de valores repetidos e armazenando apenas o valor e a quantidade de vezes que ele se repete. Por exemplo, se tivermos uma coluna com os valores “Solteiro, Solteiro, Solteiro, Casado, Casado”, o RLE armazenaria apenas “Solteiro (3), Casado (2)”. Isso reduz drasticamente o espaço de armazenamento necessário para colunas com muitos valores repetidos em sequência.
Primeiro, vamos criar uma tabela para o EstadoCivil
|
1 2 3 4 5 6 |
-- Criar uma tabela com uma coluna de estado civil e outra coluna de idade CREATE TABLE EstadoCivil ( Id INT IDENTITY(1,1), EstadoCivil VARCHAR(20), Idade INT ); |
Agora vamos inserir um milhão de linhas na tabela
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
-- Inserir 1 milhão de linhas na tabela DECLARE @i INT = 1; WHILE @i <= 1000000 BEGIN INSERT INTO EstadoCivil (EstadoCivil, Idade) VALUES (CASE WHEN @i % 3 = 0 THEN 'Solteiro' WHEN @i % 3 = 1 THEN 'Casado' ELSE 'Divorciado' END, CASE WHEN @i % 5 = 0 THEN 20 WHEN @i % 5 = 1 THEN 25 WHEN @i % 5 = 2 THEN 30 WHEN @i % 5 = 3 THEN 35 ELSE 40 END); SET @i += 1; END; |
Validando o espaço da tabela antes da criação do indice columnstore
|
1 2 |
-- Verificar o tamanho da tabela antes de criar o índice Columnstore EXEC sp_spaceused 'EstadoCivil'; |

Criando o indice columnstore
|
1 2 |
-- Criar o índice Columnstore CREATE CLUSTERED COLUMNSTORE INDEX CCI_EstadoCivil ON EstadoCivil; |
Verificando o espaço da tabela depois da criação do indice columnstore
|
1 2 |
-- Verificar o tamanho da tabela após criar o índice Columnstore EXEC sp_spaceused 'EstadoCivil'; |

Agora vamos ver como ficou a taxa de compressão do indice columnstore
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
-- Verificar a taxa de compressão do Columnstore SELECT OBJECT_NAME(object_id) AS Tabela, row_group_id, total_rows, deleted_rows, CASE WHEN total_rows = 0 THEN 0 ELSE (deleted_rows * 100) / total_rows END AS PercentualDeletado, CASE WHEN total_rows = 0 THEN 0 ELSE (1 - (size_in_bytes * 1.0 / (total_rows * 8))) * 100 END AS TaxaCompressao FROM sys.column_store_row_groups WHERE object_id = OBJECT_ID('EstadoCivil'); |

Perceba que tivemos uma taxa de compressão de 66% se comparado a uma tabela comum, é um bom número, mas poderia ser melhor, a compressão nesse teste não foi maior porque temos a coluna ID (um auto incremento) que tem alta cardinalidade, ou seja, os valores não se repetem, nesse teste apesar de termos obtido um ganho expressivo, sem o ID poderia ser ainda melhor.
Vamos agora recriar a tabela e fazer o teste (Sem o ID) com um índice rowstore com compressão e depois criarmos o clustered columnstore índex para comparar os resultados.
Criando a tabela
|
1 2 3 4 5 |
-- Criar uma tabela sem ID com uma coluna de estado civil e outra coluna de idade CREATE TABLE EstadoCivil ( EstadoCivil VARCHAR(20), Idade INT ); |
Populando os registros
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
-- Verificar a taxa de compressão do Columnstore SELECT OBJECT_NAME(object_id) AS Tabela, row_group_id, total_rows, deleted_rows, CASE WHEN total_rows = 0 THEN 0 ELSE (deleted_rows * 100) / total_rows END AS PercentualDeletado, CASE WHEN total_rows = 0 THEN 0 ELSE (1 - (size_in_bytes * 1.0 / (total_rows * 8))) * 100 END AS TaxaCompressao FROM sys.column_store_row_groups WHERE object_id = OBJECT_ID('EstadoCivil'); |
Criando o índice clustered rowstore com compressão
|
1 2 |
CREATE CLUSTERED INDEX CCI_EstadoCivil ON EstadoCivil (EstadoCivil, Idade) WITH(DATA_COMPRESSION = PAGE) |
Verificando tamanho da tabela

Dropando o índice rowstore
|
1 |
DROP INDEX CCI_EstadoCivil ON EstadoCivil |
Criando um índice Clustered Columnstore
|
1 2 |
-- Criar o índice Columnstore CREATE CLUSTERED COLUMNSTORE INDEX CCI_EstadoCivil ON EstadoCivil; |
Verificando o tamanho da tabela

|
1 2 3 4 |
-- Criando índice clustered columnstore com columnstore_archive CREATE CLUSTERED COLUMNSTORE INDEX CCI_EstadoCivil ON EstadoCivil WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE); |

Quando eles são Heróis?
Data Warehouse e Analytics
|
1 2 3 4 5 6 7 |
SELECT YEAR(DataVenda) as Ano, SUM(ValorVenda) as TotalVendas, COUNT(*) as QtdVendas FROM VendasColumnstore WHERE DataVenda >= '2020-01-01' GROUP BY YEAR(DataVenda) |
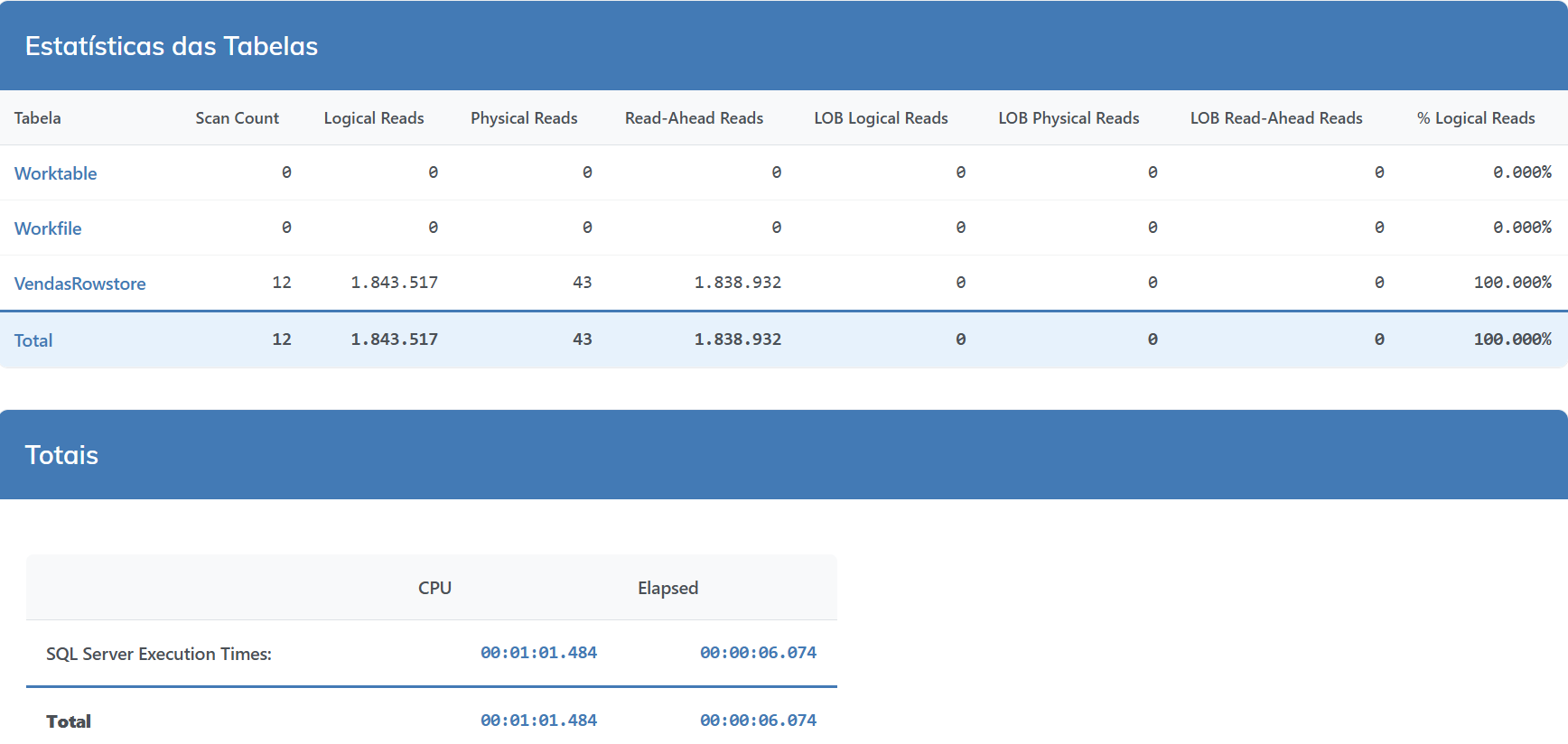
Com 200 milhões de registros, numa tabela rowstore isso pode demorar bem mais se comparado ao Columnstore.
Vamos fazer alguns testes
Temos duas tabelas, uma com um índice Columnstore criado e na outra com um índice Rowstore, veja o comparativo abaixo.

ROWSTORE
COLUMNSTORE
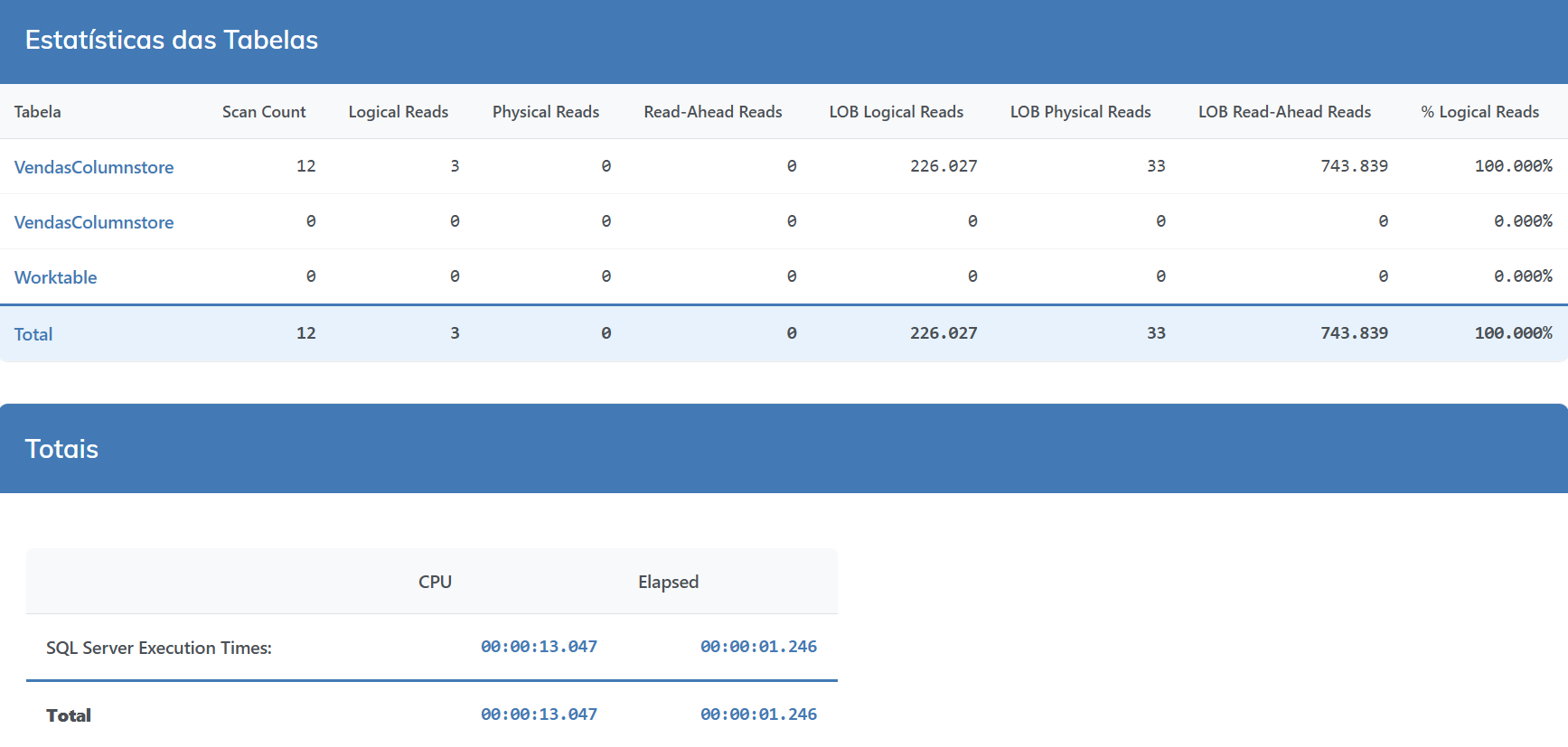
Comparativo de Desempenho

Quando eles são Vilões?
OLTP (Transações Frequentes)
Se sua aplicação faz muitos INSERT, UPDATE, DELETE pontuais, esqueça os Columnstore. Eles são péssimos para isso.
Exemplo :
|
1 2 3 4 |
-- Isso pode ser LENTO com Columnstore UPDATE Clientes SET Nome ='João Silva' WHERE ID = 12345 |
Exemplo :
|
1 2 |
-- Melhor com rowstore tradicional SELECT * FROM Pedidos WHERE NumeroPedido = 'PED123456' |
Tabelas pequenas
Limitações de tipos de dados
- text, ntext, image
- varchar(max), nvarchar(max) (em versões antigas)
- xml
- uniqueidentifier (SQL Server 2012)
Tipos de Columnstore: Clustered vs Nonclustered
Clustered Columnstore Index
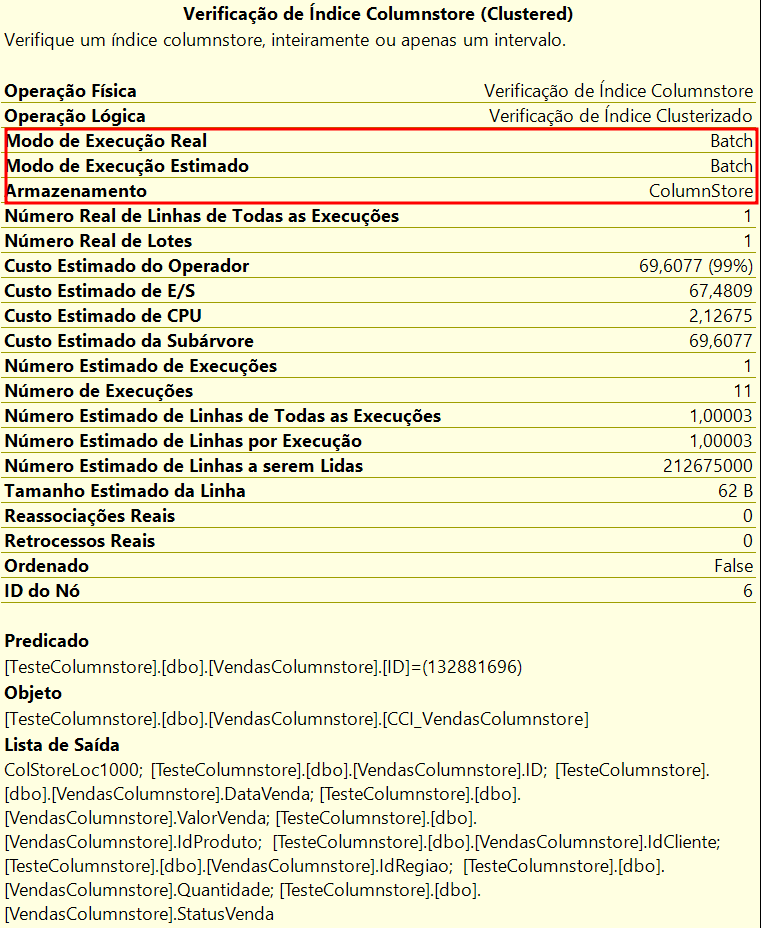
|
1 2 3 |
-- Criando um Clustered Columnstore CREATE CLUSTERED COLUMNSTORE INDEX CCI_VendasColumnstore ON VendasColumnstore |
Nonclustered Columnstore Index
Exemplo :
|
1 2 3 |
-- Criando um Nonclustered Columnstore CREATE NONCLUSTERED COLUMNSTORE INDEX NCCI_Vendas ON Vendas (DataVenda, ValorVenda, IdProduto, IdCliente) |
Batch Mode
Uma das grandes vantagens dos Columnstore é o Batch Mode Processing. Ao invés de processar linha por linha, o SQL Server processa cerca de 900 linhas por vez. É como se ao invés de carregar um caminhão caixa por caixa, você carregasse 900 caixas de uma vez.
Segment Elimination
Exemplo :
|
1 2 3 4 5 6 7 8 9 |
-- Se um segment tem vendas de Jan-2020 a Mar-2020 -- Esta query nem vai ler esse segment: SELECT DataVenda, SUM(ValorVenda) FROM VendasColumnstore GROUP BY DataVenda WHERE DataVenda >= '20250101' AND DataVenda < '20250201' GROUP BY DataVenda |
Isso é uma mágica pura. O SQL Server já sabe que não precisa nem olhar aquele pedaço dos dados.

Mas, nem tudo sâo flores, existem algumas limitaçôes para o Segment Elimination que dependendo de como foi criado o seu índice columnstore pode não funcionar corretamente. Eu estava tendo um pouco de dificuldade para conseguir ver esse recurso funcionando na prática, então li um artigo do Klaus Aschenbrenner que foi bem esclarecedor.
Segue o link do artigo, caso queiram dar uma conferida.
Para este recurso funcionar, foi necessário recriar o índice columnstore com o parâmetro (MAXDOP = 1)
|
1 2 |
CREATE CLUSTERED COLUMNSTORE INDEX CCI_VendasColumnstore ON VendasColumnstore WITH (DROP_EXISTING = ON,MAXDOP = 1) |
Segundo o Klaus, isso pode acontecer porque quando você cria o índice normalmente no operador do Columnstore Index insert ele é aplicado em paralelo (várias threads ao mesmo tempo) e isso acaba prejudicando a ordem sequencial de inserção. Com o MAXDOP = 1, você obriga o SQL a criar o índice utilizando apenas uma thread e isso faz que os registros sejam inseridos sem perder a sequencia, proporcionando que o Segment Elimination funcione melhor.
Queries úteis
Vou deixar aqui alguns scripts que uso no dia a dia para monitorar columnstore:
Verificando fragmentação
Segue um script que pode te ajudar a monitorar a fragmentação dos índices columnstore
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT i.object_id, OBJECT_NAME(i.object_id) AS TableName, i.index_id, i.name AS IndexName, 100 * (ISNULL(SUM(rg.deleted_rows),0)) / NULLIF(SUM(rg.total_rows),0) AS FragmentationPercent FROM sys.indexes i INNER JOIN sys.dm_db_column_store_row_group_physical_stats rg ON i.object_id = rg.object_id AND i.index_id = rg.index_id WHERE i.type IN (5,6) -- Columnstore indexes GROUP BY i.object_id, i.index_id, i.name ORDER BY FragmentationPercent DESC |

Verificando compressão
Verificar a compressão dos índices columnstore é importante porque ela pode afetar diretamente o desempenho e o armazenamento do banco de dados. Uma boa compressão pode reduzir o tamanho do armazenamento necessário, melhorar o desempenho de consultas e reduzir o uso de recursos, enquanto uma compressão inadequada pode levar a problemas de desempenho e aumento do armazenamento necessário. Além disso, a compressão eficaz pode variar dependendo do tipo de dados e da estrutura do índice.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT t.name AS TableName, p.rows AS [RowCount], (SUM(a.total_pages) * 8) / 1024 AS TotalSpaceMB, (SUM(a.used_pages) * 8) / 1024 AS UsedSpaceMB, p.data_compression_desc FROM sys.tables t INNER JOIN sys.indexes i ON t.object_id = i.object_id INNER JOIN sys.partitions p ON i.object_id = p.object_id AND i.index_id = p.index_id INNER JOIN sys.allocation_units a ON p.partition_id = a.container_id WHERE i.type IN (5,6) -- Columnstore GROUP BY t.name, p.rows,p.data_compression_desc ORDER BY TotalSpaceMB DESC |

Forçando compressão do Deltastore
Forçar a compressão do Deltastore pode ser útil para reduzir o tamanho do armazenamento necessário e melhorar o desempenho de consultas, pois o Deltastore é uma estrutura de dados que armazena as alterações nos dados do columnstore. Ao forçar a compressão, você pode garantir que as alterações sejam compactadas e armazenadas de forma eficiente, reduzindo o impacto no desempenho e no armazenamento. No entanto, é importante considerar que a compressão forçada pode ter um custo em termos de recursos de CPU e pode afetar o desempenho de inserção e atualização de dados.
Abaixo um exemplo de como forçar a compressão do Deltastore:
Exemplo :
|
1 2 3 |
-- Move dados do deltastore para columnstore ALTERINDEX CCI_FactVendas ON FactVendas REORGANIZE WITH (COMPRESS_ALL_ROW_GROUPS = ON) |
Limitações que você deve conhecer
SQL Server 2012 (primeira versão)
A primeira versão tinha limitações severas. A tabela ficava read-only com nonclustered columnstore, não suportava clustered columnstore atualizável, e tinha muitas limitações de tipos de dados.
Versões atuais (2016+)
Muito mais flexível. Suporte a updates/deletes, mais tipos de dados suportados, e disponível em todas as edições (não só Enterprise).
A ordem de inserção também pode afetar o desempenho das consultas, pois o columnstore pode utilizar técnicas de eliminação de segmentos (segment elimination) para reduzir a quantidade de dados que precisam ser lidos durante uma consulta. Se os dados estiverem ordenados de acordo com as colunas utilizadas nas consultas, o columnstore pode eliminar mais eficientemente os segmentos que não são relevantes para a consulta.
Mas será que a diferença é tão grande assim na prática?
Vamos aos testes
|
1 2 3 4 5 6 7 8 9 10 11 12 |
-- dados ordenados por data INSERT INTO FatoVendas SELECT DataVenda, ValorVenda, IDProduto, IdCliente, IdRegiao, Quantidade, DescricaoProduto, StatusVenda FROM VendasColumnstore ORDER BY DataVenda |
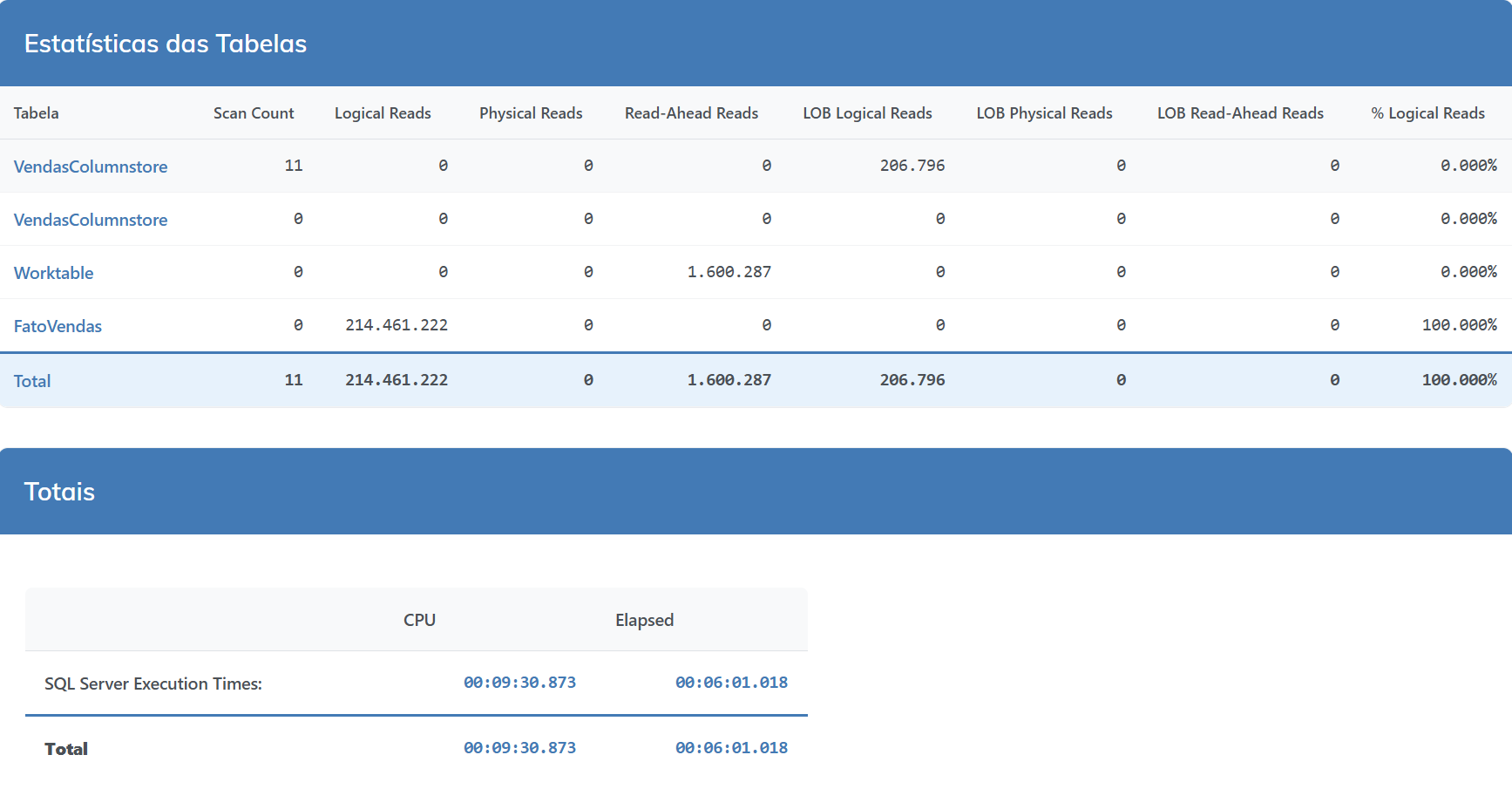
|
1 2 3 4 5 6 7 8 9 10 11 12 |
-- dados aleatórios INSERT INTO FatoVendas SELECT DataVenda, ValorVenda, IDProduto, IdCliente, IdRegiao, Quantidade, DescricaoProduto, StatusVenda FROM VendasColumnstore ORDER BY New_ID() |
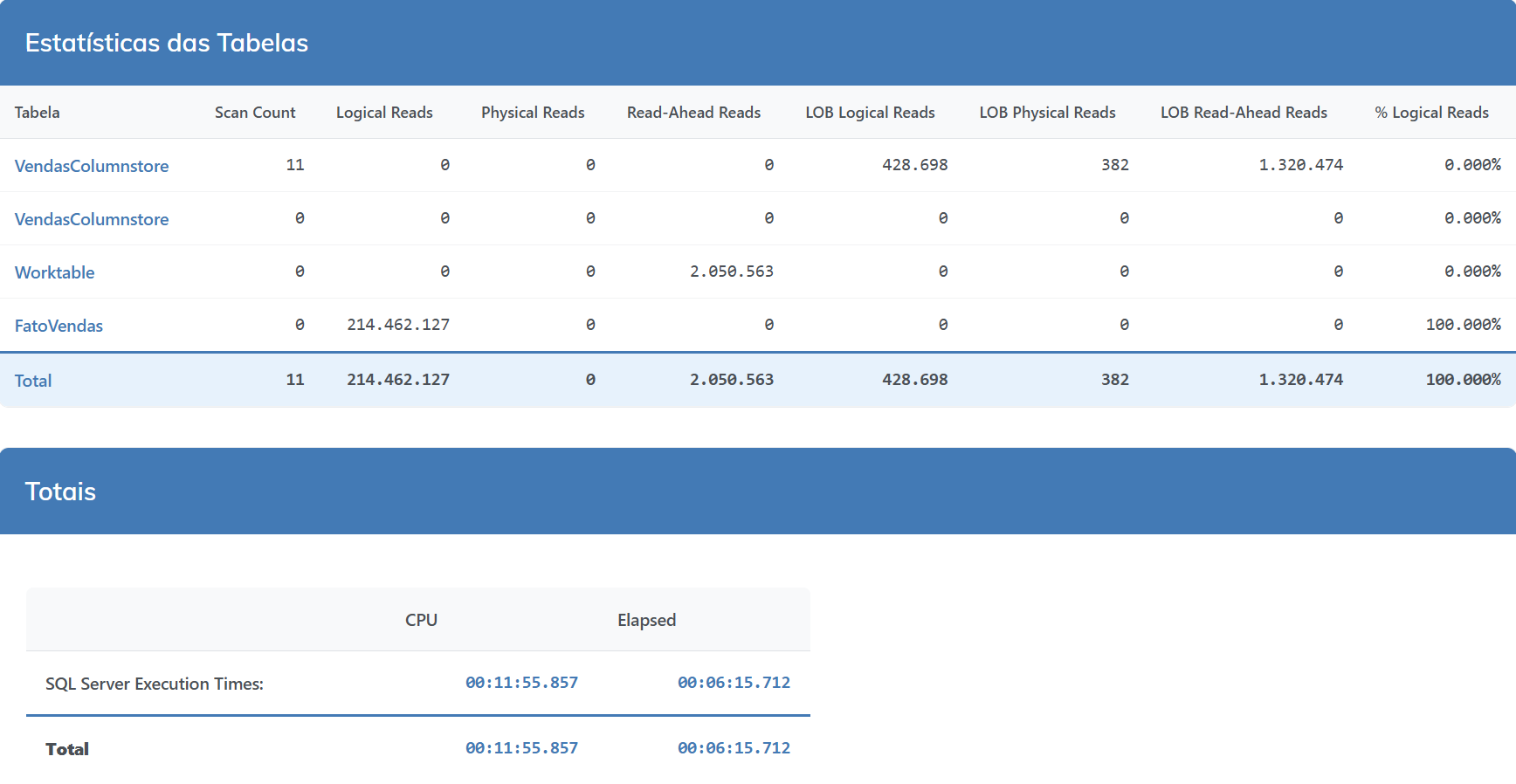
Comparativo de Desempenho
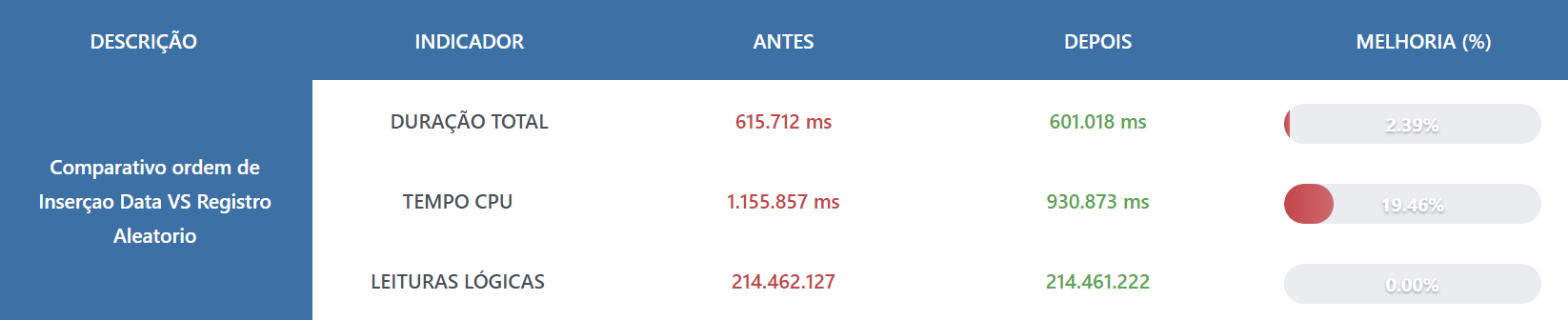
É… nem tanto.. claro, 19% de CPU é uma singela diferença, mas sendo sincero, acho que não muda tanto o resultado final.
O Particionamento da tabela aliado ao Índex Columnstore pode ajudar na performance das consultas?
O particionamento é tipo um superpoder quando se trabalha com columnstore. Ele ajuda a dividir os dados em pedaços menores e mais gerenciáveis, o que torna as consultas mais rápidas e eficientes. Adicionalmente, você pode fazer manutenção e atualizações em apenas uma parte dos dados, em vez de ter que mexer em tudo. Isso é especialmente útil quando se lida com grandes volumes de dados, pois ajuda a reduzir o tempo de consulta e a carga de trabalho no servidor.
Vamos ver na prática uma consulta de vendas dessa nossa tabela de estudos (200 milhões de linhas) buscando dados dos anos de 2020 a 2022.
Exemplo :
|
1 2 3 4 5 6 7 8 9 |
SELECT YEAR(DataVenda) AS Ano, SUM(ValorVenda) AS FaturamentoTotal FROM VendasColumnstore WHERE DataVenda >= '2020-01-01' AND DataVenda < '2023-01-01' GROUP BY YEAR(DataVenda) |
Performance sem particionamento e sem columnstore
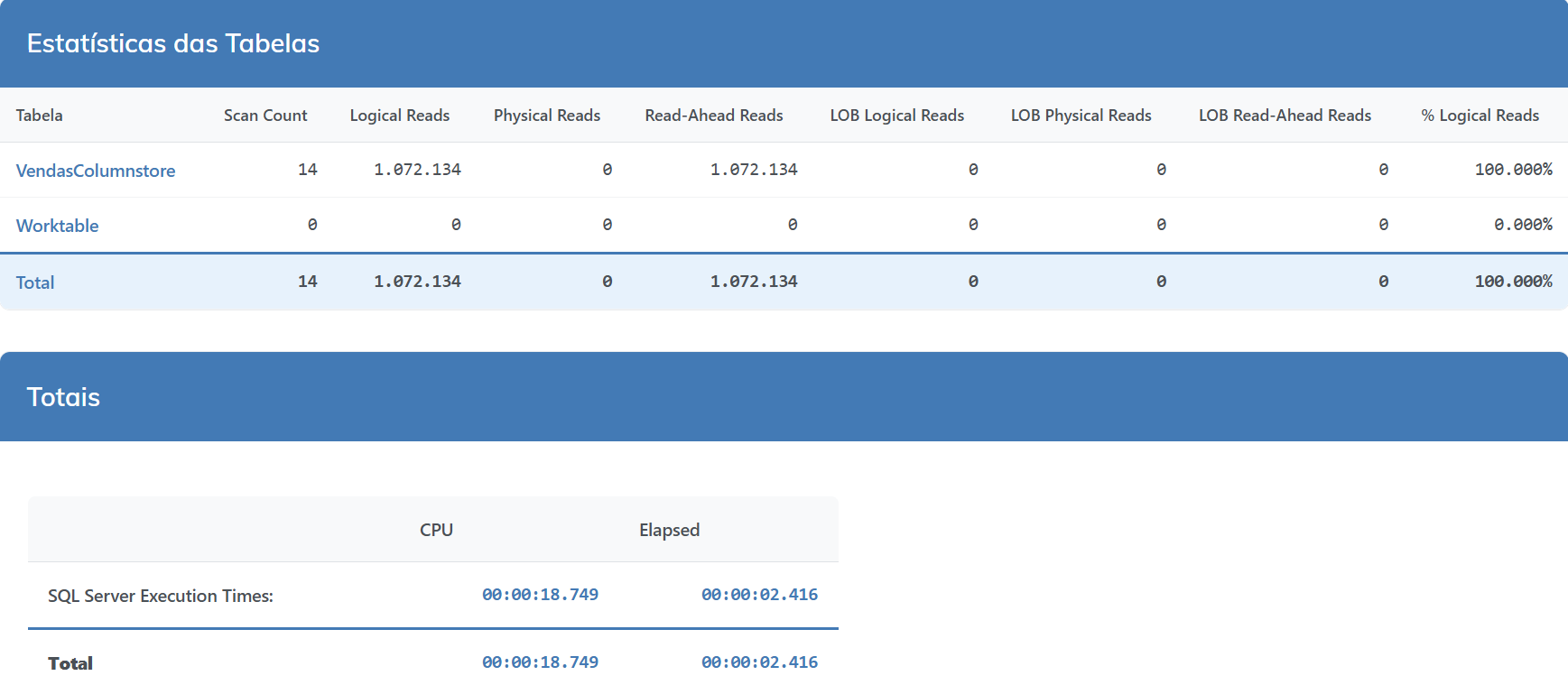
Agora vamos aplicar o particionamento por Data e criar o índice columnstore com a nossa função de particionamento.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
-- Combinando particionamento com o columnstore CREATE PARTITION FUNCTION pf_Data (DATE) AS RANGE RIGHT FOR VALUES ('2020-01-01', '2021-01-01', '2022-01-01', '2023-01-01', '2025-01-01') CREATE PARTITION SCHEME ps_Data AS PARTITION pf_Data ALL TO ('PRIMARY') CREATE CLUSTERED COLUMNSTORE INDEX CCI_VendasColumnstore ON VendasColumnstore ON ps_Data(DataVenda) |
Performance tabela particionada + índice columnstore
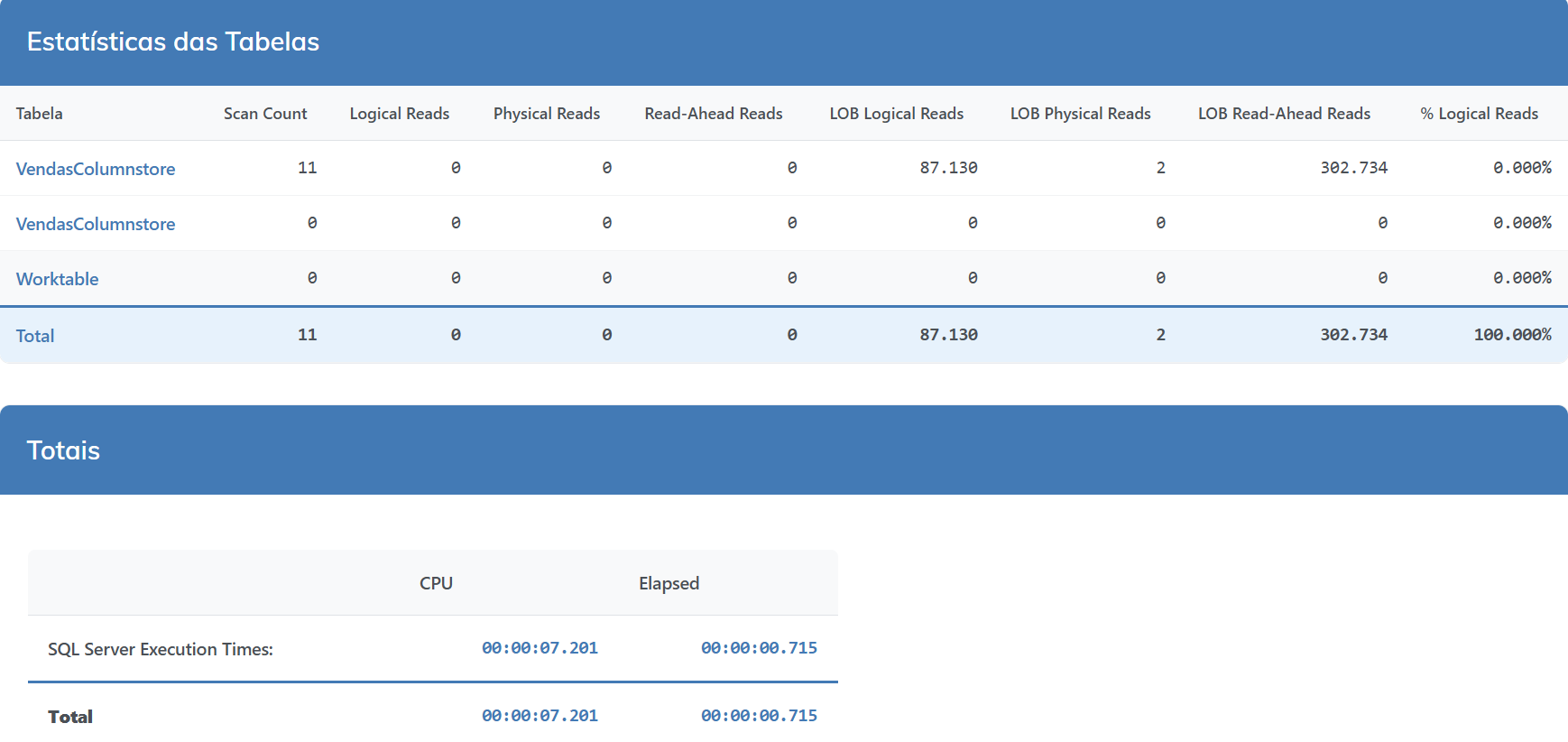
Comparativo de Desempenho

E ai, faz uma boa diferença, né?
Veredicto final: Herói ou vilão? Batman ou Coringa?
A resposta é: DEPENDE DO CONTEXTO.
Se você está lutando com performance em relatórios, Analytics ou Data Warehouse, os Columnstore podem ser seus heróis. Mas se você tentar forçá-los numa aplicação OLTP, eles rapidamente se tornarão vilões.
A tecnologia evoluiu muito desde 2012. No SQL Server 2019 e versões mais recentes, muitas limitações foram removidas, e até mesmo workloads mistos (HTAP – Hybrid Transactional/Analytical Processing) se tornaram viáveis.
Minha dica final: teste, teste, teste! Cada ambiente é único, e só testando você vai saber se os Columnstore são heróis ou vilões no seu cenário específico.
Conta aí nos comentários!
Bom, é isso, espero que tenham gostado!
Qualquer dúvida deixe os comentários.
Referências:





