Como simular o plano de execução de um índice no SQL Server
 Tempo de leitura: 6 minutos
Tempo de leitura: 6 minutosOlá Pessoal,
Espero que estejam todos bem!! ?
No post de hoje, falaremos sobre uma dica no SQL Server relacionada a criação de índices.
É possível simular o plano de uma query sem necessariamente criar o índice no SQL Server? A resposta para isso é: SIM!!!!!
Primeiramente, se você não conhece muito sobre o conceito de Tuning e Índices no SQL Server, sugiro como conteúdo obrigatório dar uma boa lida antes de prosseguir com a leitura nesses artigos, ok?
https://www.dirceuresende.com/blog/sql-server-introducao-ao-estudo-de-performance-tuning/
https://www.dirceuresende.com/blog/entendendo-o-funcionamento-dos-indices-no-sql-server/
#QueHomem esse Dirceu, só tem artigo fera!!!
Sem mais delongas, vamos lá!!
Como assim Gustavo? Simular o plano de uma query sem criar o índice?? Tá doido homem?
Imaginem o cenário: Você possui um ambiente altamente transacional, com tabelas gigantescas, em determinado momento do dia você identifica que tem uma consulta onerando o seu ambiente que está fazendo um SCAN em uma tabela do seu banco de dados. Você então encontra uma oportunidade para melhorar a performance desta query através da criação de um índice. No entanto, você não tem um ambiente de Homologação para testar se esse seu índice de fato será efetivo.
O que você faz? Sai criando o índice em produção?
Quais transtornos isso poderia te gerar?
- Se seu ambiente é altamente transacional, certamente você poderá enfrentar problemas com bloqueios durante a criação do seu índice.
- Se sua tabela for muito grande, certamente, o processo para a criação deste índice pode demorar bons minutos e até horas.
- Se o otimizador de consultas resolver não utilizar o índice que você criou, um bom espaço em disco deverá ficar reservado para aquele índice desnecessariamente, sem contar que as suas operações de escrita poderão demorar mais devido ao query optimizer ter que preencher o registro mais uma vez nesse índice que foi criado.
- Você pode ter dificuldade em dropar esse índice enquanto a tabela estiver sendo utilizada.
Tá bom Gustavo, você me convenceu, mas e aí? Teria como simular isso? Conta ai pra gente!
Se você está fazendo um trabalho de Tuning em um ambiente de missão crítica. Eu altamente recomendo em tudo o que você fizer, testar um milhão de vezes em homologação antes de aplicar em produção.
Se NÃO existir essa possibilidade, aí sim, seguir os passos abaixo:
Já ouviu falar de índices hipotéticos?
Sim meus queridos amigos, a técnica que explicaremos à diante é derivada desse tipo de índice. Em resumo, um índice hipotético não é persistido no disco, ele apenas mantém as estatísticas.
Os índices hipotéticos retêm estatísticas do nível de coluna e são mantidos e usados pelo Orientador de Otimização do Mecanismo de Banco de Dados..
Maiores informações no link abaixo :
Um outro mecanismo que utiliza bastante índice hipotético é o famoso DTA (Database Engine Tuning Advisor) uma ferramenta presente no SQL Server que faz o gerenciamento e até cria índices no ambiente a partir de algumas análises que ele faz do repositório de consultas em cache. No entanto, não falaremos sobre o DTA neste momento.
Segue um link sobre maiores informações sobre a utilização do DTA :
Então, vamos a um exemplo prático do que falamos até aqui, suponhamos que esta query esteja fosse o ofensor do nosso ambiente.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
Use [StackOverFlow2013] GO SELECT PT.[Type], Po.Score, Po.Title FROM StackOverflow2013.dbo.Posts Po INNER JOIN StackOverflow2013.dbo.PostTypes PT ON PT.Id = Po.PostTypeId WHERE Po.Score > 500; |
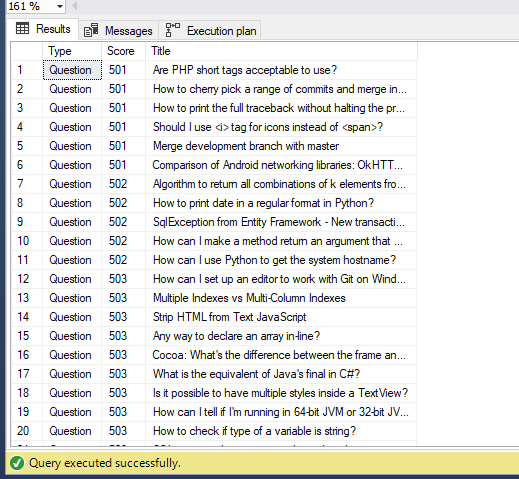
Durante a análise percebemos que se criarmos um índice de cobertura na tabela “Posts” pelos campos “Score” e “PostTypeId” e com o campo “Title” no include, conseguiremos melhorar a performance da consulta significativamente. Essa tabela “Posts” possui 17 milhões de linhas.
|
1 |
sp_spaceused 'dbo.Posts' |
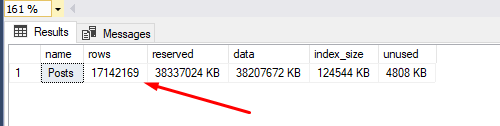
Tá Gustavo, agora como eu sei que meu índice vai realmente ser efetivo?
Bom, vamos lá. Primeiramente faremos um select na sys.databases para descobrir qual é o ID da nossa base de dados StackOverFlow2013.
|
1 |
select * from sys.databases |

Ótimo, descobrimos que o ID da nossa base é o 6. Guarde este número, iremos utilizá-lo mais à frente.
Vamos agora montar a sintaxe do nosso índice:
|
1 2 3 4 5 6 7 |
CREATE NONCLUSTERED INDEX [SK01_POSTS] ON [dbo].[Posts] ([Score]) INCLUDE ([Title]) WITH (STATISTICS_ONLY = -1,DROP_EXISTING=OFF) |
Execute o comando.
Reparem neste trecho, STATISTICS_ONLY = -1, é aqui que está a nossa mágica!! quando criamos o índice informando o parâmetro STATISTICS_ONLY = -1, o SQL fará a criação apenas das estatísticas do índice, logo a criação do índice não será “persistida” no disco.
Hummmm… está começando a ficar interessante, conta mais!!!
Agora faremos o seguinte, execute a consulta abaixo (No meu caso, a tabela que estou querendo capturar as informações é a “Posts”, mas fique à vontade em utilizar da maneira que desejar de acordo com a tabela que estiver otimizando no seu ambiente).
|
1 2 3 4 5 |
SELECT name, id, Indid, Dpages, rowcnt FROM sysindexes WHERE id = object_id('Posts') |
Ao executar a instrução, recebi os seguintes resultados:
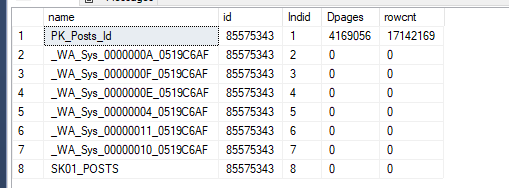
Lembram que eu solicitei para guardarem o ID do seu banco na sys.databases, pois bem, chegou a hora de utilizarmos.
No início deste post eu mencionei que o nosso objetivo era simular como vai ficar o nosso plano de execução com a criação de um índice, agora é a hora.
Pois bem, existe um comando chamado DBCC AUTOPILOT que irá nos ajudar no nosso objetivo, execute a seguinte sintaxe abaixo, preencha os valores no seu ambiente de acordo com a explicação que será feita mais abaixo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
DBCC AUTOPILOT (0, 6, 85575343, 1) -- Índice cluster DBCC AUTOPILOT (0, 6, 85575343, 8) -- Índice Hipotético SK01_Posts GO SET AUTOPILOT ON GO SELECT PT.[Type], Po.Score, Po.Title FROM StackOverflow2013.dbo.Posts Po INNER JOIN StackOverflow2013.dbo.PostTypes PT ON PT.Id = Po.PostTypeId WHERE Po.Score > 500; GO SET AUTOPILOT OFF GO |
Por dentro da sintaxe do comando:
DBCC AUTOPILOT (0 – Indica o nosso type_id vamos manter 0,
6 – Representa o nosso database id,
85575343 – Simboliza a posição do id do nosso índice na sysindexes,
1 – Representa a coluna Indid (indicador do id) na sysindexes).
Vale informar, esse comando não é documentado pela Microsoft.
Feito isso, informamos duas vezes a linha com o DBCC AUTOPILOT, uma para o nosso índice clustered e outra para o índice hipotético.
Agora, vamos “ligar” o nosso comando SET AUTOPILOT ON
Sempre adicionaremos o GO para indicar que iremos para próxima instrução, na sequência informamos a consulta que desejamos executar e depois desligamos o nosso comando, SET AUTOPILOT OFF.
O resultado deverá ser exibido assim:

Clicando neste hiperlink que o SQL gerou, teremos acesso ao nosso plano de execução.
Eis como ficará o nosso plano:

Gustavo, que magia negra foi essa??
Sim, conseguimos “prever” como ficará o plano de execução da nossa consulta, sem ter persistido o índice no disco.
Já imaginaram como isso pode nos ajudar no dia a dia?
Mas vamos lá… Será que se criarmos esse índice pra valer no ambiente o plano vai ficar assim, e a performance da consulta? Ficou melhor ou pior que antes ? Bora fazer um teste?
|
1 2 3 4 5 6 7 |
CREATE NONCLUSTERED INDEX [SK01_POSTS_PERSISTED] ON [dbo].[Posts] ([Score],[PostTypeId]) INCLUDE ([Title]) WITH (DATA_COMPRESSION = PAGE,DROP_EXISTING=OFF, MAXDOP= 4) |
Informei o parâmetro MAXDOP = 4 no índice para paralelizar a criação do comando e ir mais rápido. (Esse recurso pode ser utilizado nas versões do SQL Server Enterprise ou Developer).
Seguem os comparativos :
Estatísticas de execução Antes :
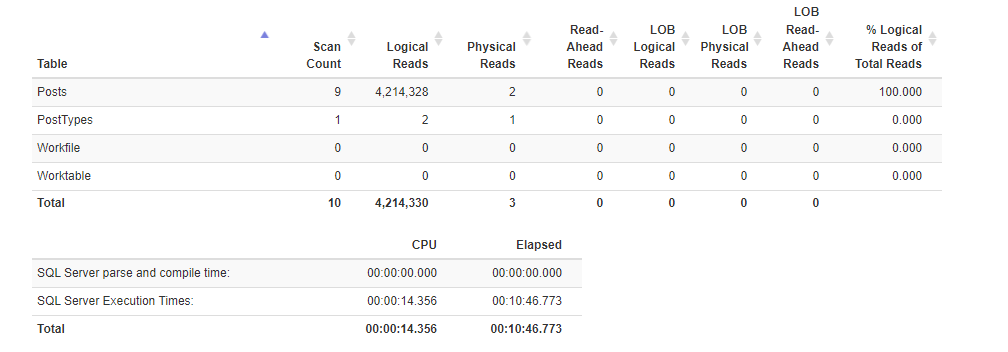
Estatísticas de execução Depois :
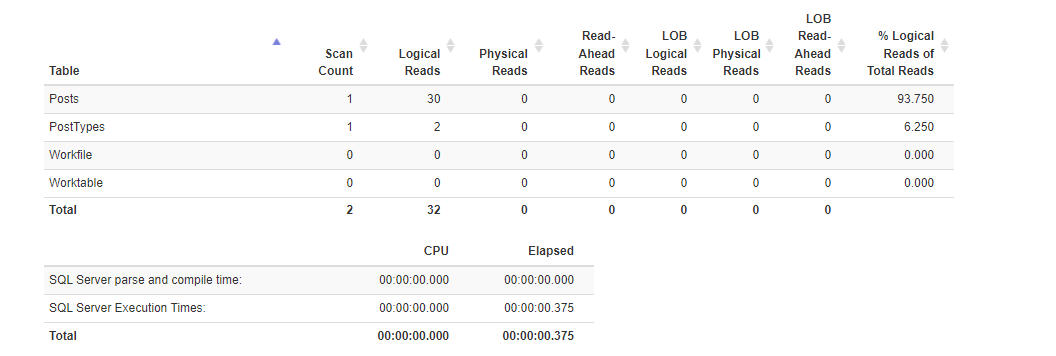
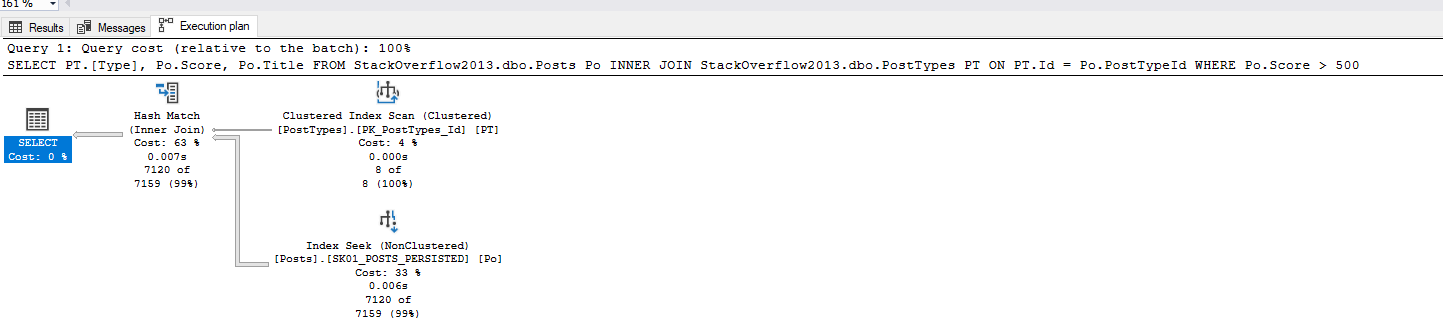
Plano com o índice criado :
Gustavo, se isso não é documentado, onde é que você descobriu essa valiosa informação??
Nosso gracioso mestre, idolatrado por toda comunidade SQL Server, devorador de torresmos, dono de uma das maiores mentes na qual já tive o prazer de conhecer Fabiano Amorim.
Me lembro que vi isso na plataforma de cursos da Power Tuning em meio a uma de suas (até o momento desse post 175 dicas).
https://cursos.powertuning.com.br/bundles?bundle_id=dicas-de-performance-no-sql-server
Corre lá, 15% de desconto se comprar o bundle com os 07 cursos.
Também sei que ele blogou sobre isso em 2011, segue o link caso queiram conferir o artigo dele.
https://blogfabiano.com/2011/08/24/undocumentedstatistics_only-dbcc-autopilot-and-set-autopilot/
Segue uma foto do dia em que eu conheci esse lindo pessoalmente no “Treinamento de Internals IO”. Que honra ter uma foto com esse cara!!!

É isso aí galera, espero que tenham gostado!!!
Se gostaram comentem!!
Um grande abraço a todos, até a próxima!!
Gustavo Larocca
Consultor SQL Server






3 comentários
Show…. Valeu Gustavo! Mais uma vez, uma ótima dica.
Parabens pelo post. Está dica é valiosa. Obrigado
Dica top, Larocca!